短信过滤 APP 开发#
本文发布在搜狐技术产品 - 短信过滤 APP 开发
一直想开发一个自己的短信过滤 APP,但是一直没有具体实施,现在终于静下心来,边开发边记录下整体的开发过程。
垃圾短信样本#
遇到的第一个问题是,既然要过滤垃圾短信,那首先要识别哪些是垃圾短信?如何识别呢?
参考之前训练识别钢管计数的经验,决定通过 CoreML 训练 Text 模型来识别,那问题来了,要训练模型的短信数据集怎么来?
一开始打算网上找到垃圾短信样本,但找了好久没找到,于是就想到用自己和家人手机里的短信,毕竟手机里短信一般不删除,也有小几千条,而且垃圾短信、推销、广告之类的应有尽有。
所以问题就变成了,如何导出 iPhone 短信?
这里笔者也查了好久,找到的第三方软件基本都是需要收费,最终发现了一个免费导出的方案。
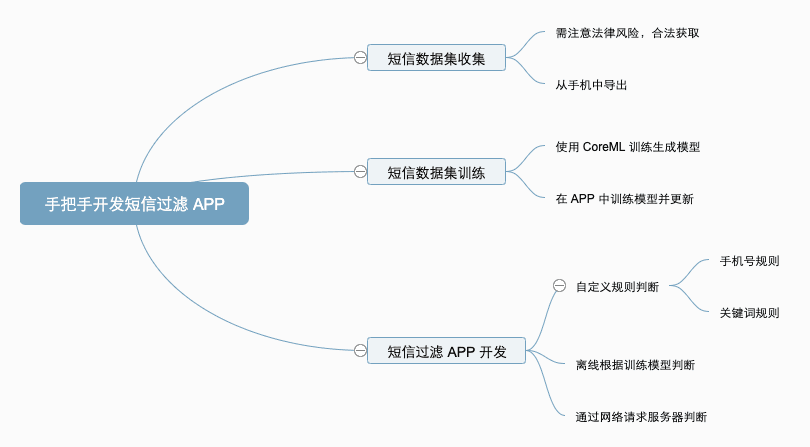
首先不加密备份手机到电脑,如下图,选中Back up all the data on your iPhone to this Mac,点击Back Up Now,等待备份完成,备份完成后,再点击Manage Backups
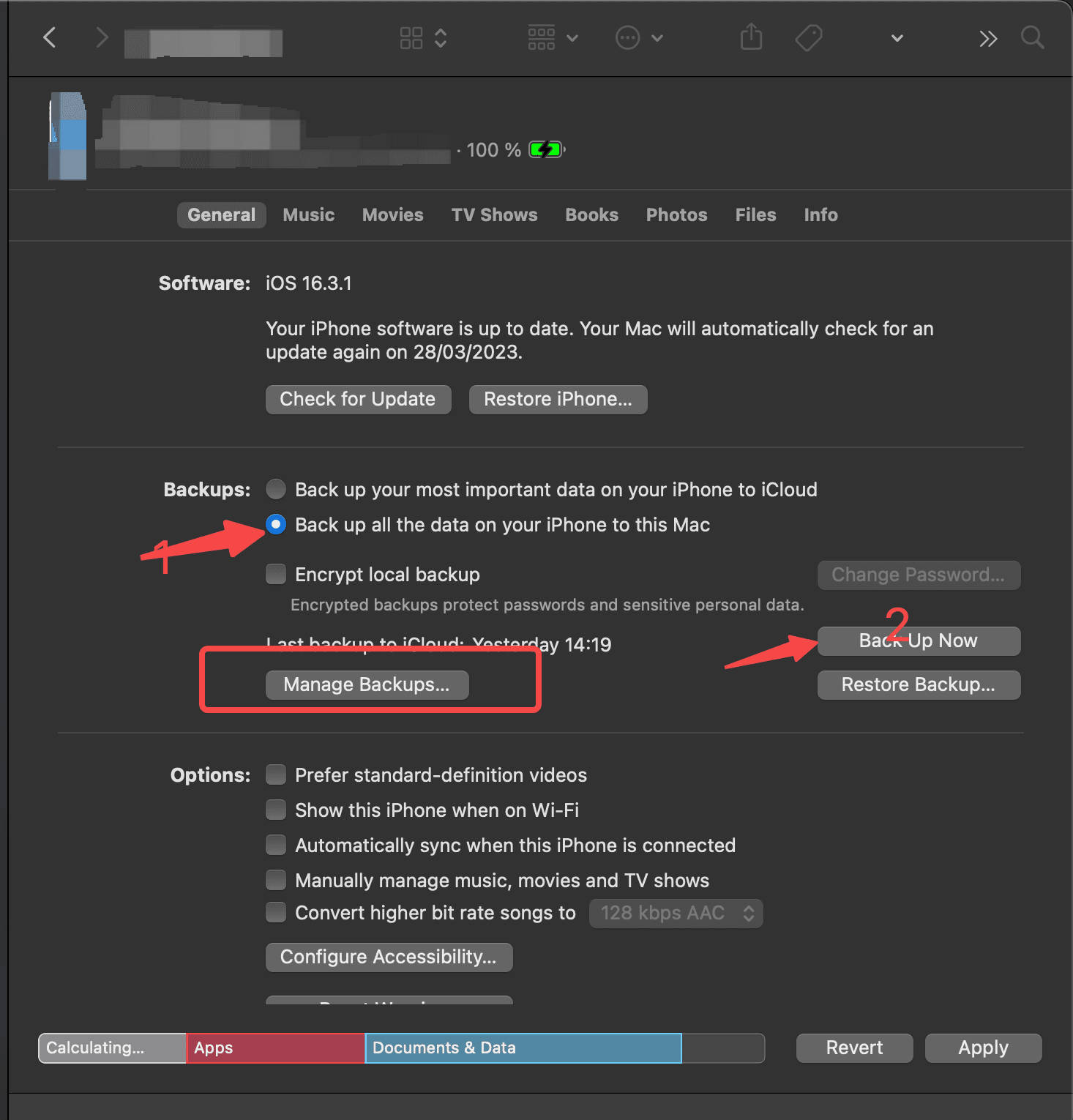
Manage Backups点击后,界面如下,可以看到已备份的记录,右键选择Show In Finder,在文件夹中打开
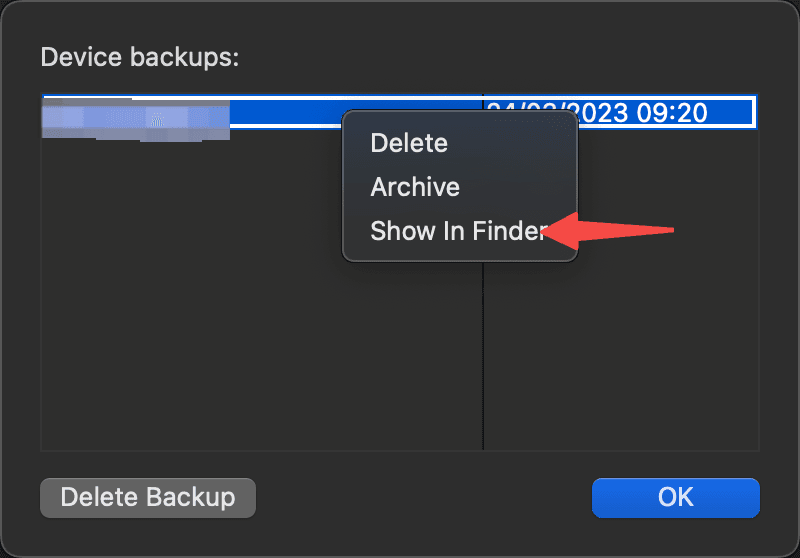
然后可以看到备份所在目录已打开,这时候需要找到文件名为3d0d7e5fb2ce288813306e4d4636395e047a3d28的文件,这个文件就是短信备份的数据库文件。然后问题来了,怎么找呢?看到备份目录一个个文件夹是不是懵,这怎么找,很简单,搜索,点击右上角的搜索,直接把这个文件名输入即可,注意搜索的范围是当前文件夹,
搜索结果如下:
然后把这个文件单独拷贝到另一个地方,比如桌面,再用数据库软件打开,比如SQLPro for SQLLite,打开如下:
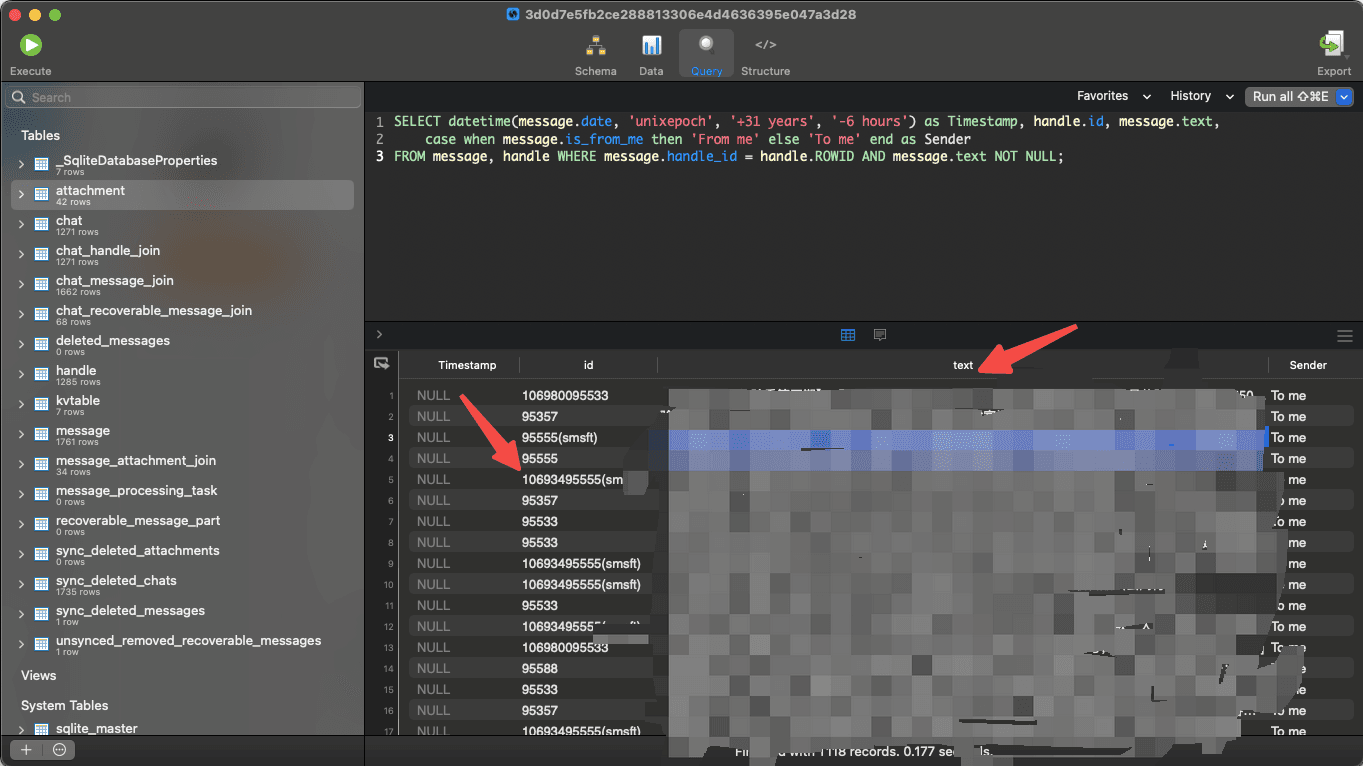
然后观察这个文件后发现,手机号和短信记录分布在不同表中,需要写一个 SQL 查出需要的内容,SQL 内容如下,参考SQL to extract messages from backup,选中上图中Query,输入命令如下:
SELECT datetime(message.date, 'unixepoch', '+31 years', '-6 hours') as Timestamp, handle.id, message.text,
case when message.is_from_me then 'From me' else 'To me' end as Sender
FROM message, handle WHERE message.handle_id = handle.ROWID AND message.text NOT NULL;
然后点击右上角的执行,可以看到,把短信都筛选出来了
然后选中所有 row,右键选择Export result set as 导出CSV,即可导出 excel 格式的文件。
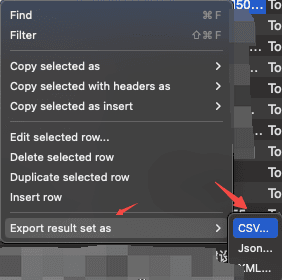
这样就获取到了所需的短信样本。
垃圾短信训练识别#
有了样本之后,再来看如何训练识别,打算使用苹果的 CoreML 识别,那么如何使用?样本格式的要求是什么样?训练需要多久?
先来看,创建一个文字训练的CoreML工程,选中 Xcode,点击Open Developer Tool,选中CoreML打开,如下图:
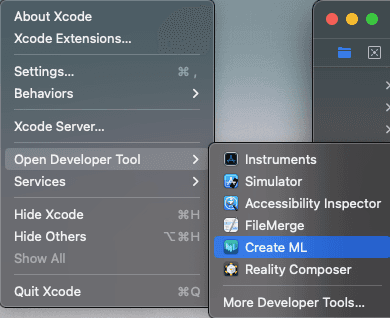
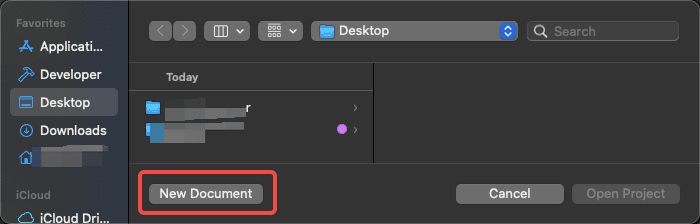
然后选择文件夹,并点击新建New Document, 如下:
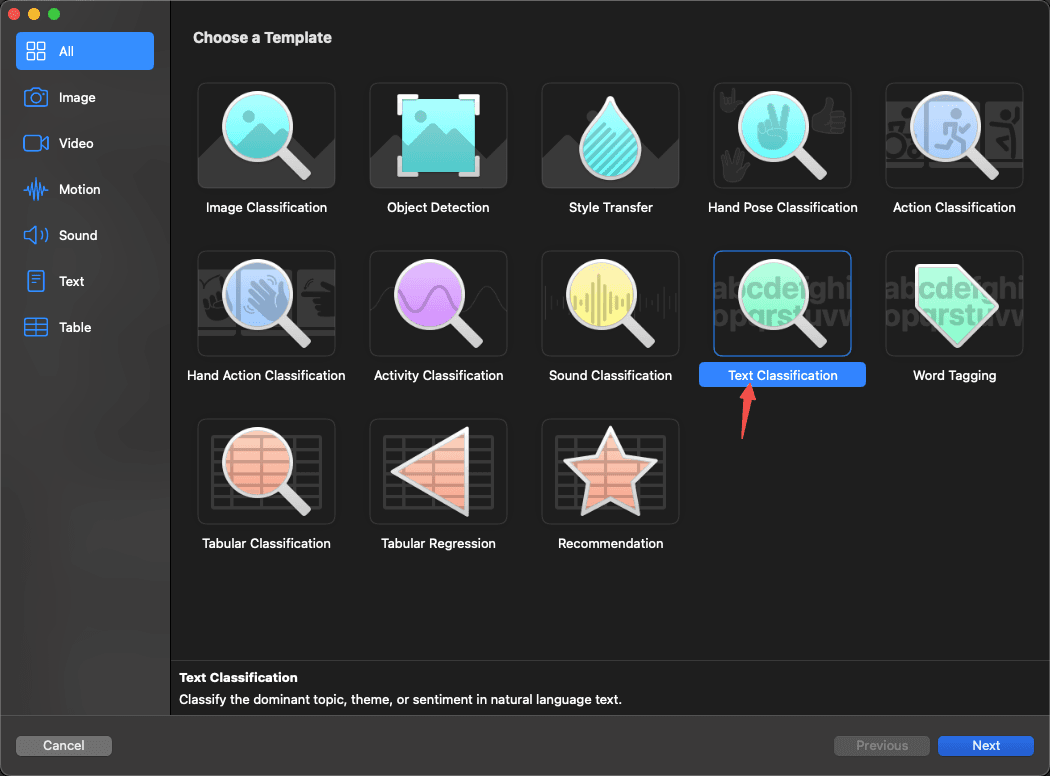
然后选中Text Classification,如下图:
接着输入项目的名字和描述,
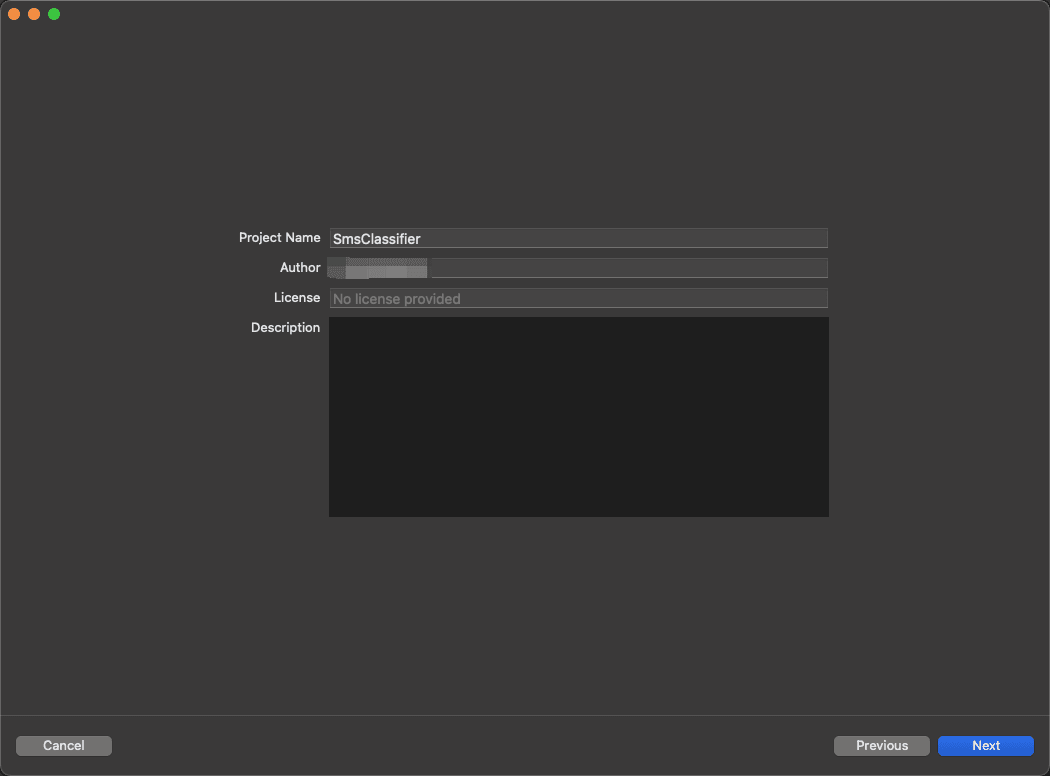
点击右下角创建,进入主界面,如下
点击Traing Data的详细说明,可以看到CoreML要求的文字识别的格式,支持JSON和CSV文件,格式如下:
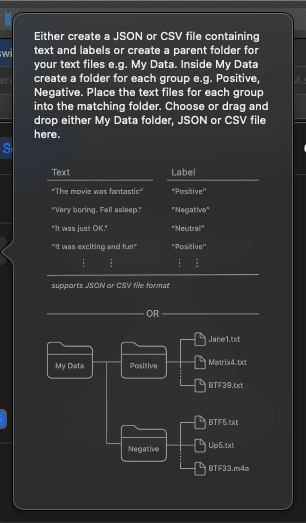
JSON 格式如下:
// JSON file
[
{
"text": "The movie was fantastic!",
"label": "positive"
}, {
"text": "Very boring. Fell asleep.",
"label": "negative"
}, {
"text": "It was just OK.",
"label": "neutral"
} ...
]
而 CSV 格式则是,一列text,一列label,
| text | label |
|---|---|
| 这是一条普通短信 | label1 |
| 这是一条垃圾短信 | label2 |
由于再前一步中,已经将短信导出为 CSV 格式,所以这里就需要把格式改为上图中格式即可,只剩下一个问题需要解决,即:label 有哪些取值?
要看 label 有哪些取值,需要先看系统短信的过滤逻辑是什么样?支持的过滤分类有哪些?否则自己想实现的分类,分组好了,最后发现系统不支持就尴尬了。
短信过滤分类#
系统短信的过滤逻辑#
参考SMS and MMS Message Filtering,可以看到,开发者是没有权限创建新分组的,只能是针对收到未知联系人的SMS或者MMS,拦截返回指定的分类。
这里需要注意的是,根据文档的说法,短信过滤不支持 iMessage 和通讯录中联系人短信的过滤,仅支持未知联系人的SMS和MMS。
短信过滤,又分为本地判断过滤和服务端判断过滤,示意图如下:
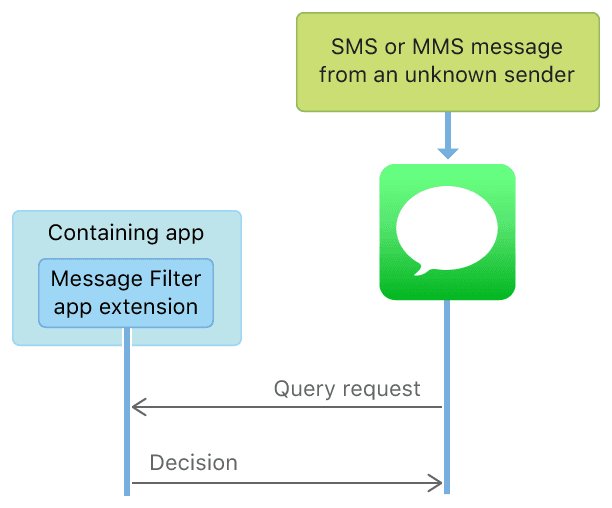
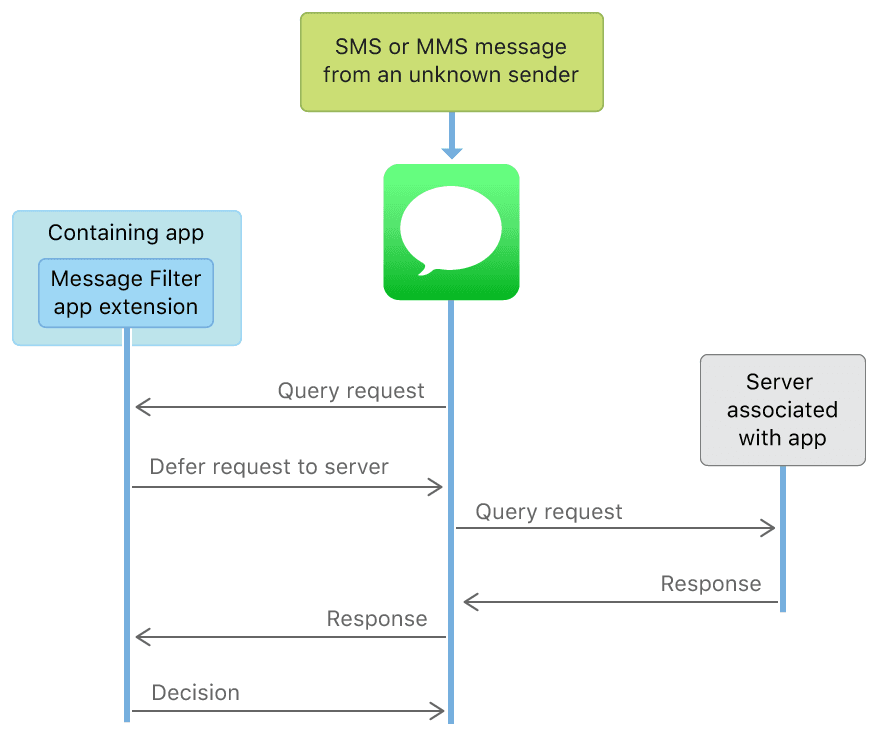
按照文档的说法,即使是服务端过滤,APP 也是不能直接访问网络的,系统会和设置的服务器交互;而且 App Extension 不能通过共享 Group 写数据,故而短信仅能在 App Extension 中获取到,不能存储,不能上传,从而保证隐私和安全。关于服务端过滤更多的实现,可以参考Creating a Message Filter App Extension。
再来看支持的过滤类型,ILMessageFilterAction
大分类支持五种:
- none
没有足够信息,不能判断,会展示信息,或进一步请求服务端判断过滤 - allow
正常展示信息 - junk
阻止正常展示信息,显示在垃圾短信分类下 - promotion
阻止正常展示信息,显示在推送信息分类下 - transation
阻止正常展示信息,显示在交易信息分类下
而其中又可以细分子分类,ILMessageFilterSubAction,具体含义可以参考ILMessageFilterSubAction
- none
- promotion 支持的子分类有
- others
- offers
- coupons
- transation 支持的子分类有
- others
- finance
- orders
- reminders
- health
- weather
- carrier
- rewards
- publicServices
这里仅针对大分类做处理,具体的子分类不做详细过滤,所以需要训练的 label 有哪些取值就很明确了,过滤垃圾短信、推广信息、交易信息,至于 none 和 allow 不做区分,统一处理为 allow,所以总共需要训练的 label 取值有以下这些:
- allow
- junk
- promotion
- transation
然后就是针对导出短信的CSV文件,针对每条短信,添加对应的 label,这里只能手工,样本的大小和 label 定义决定后续识别的准确度,同时为了后续子分类的实现,建议实事求是,不要把比如 promotion 里的分到 junk 里。。。
每条短信样本都标记好了之后,就可以导入Create ML来训练,生成需要的模型,步骤如下:
首先导入数据集
然后点击左上角的Train
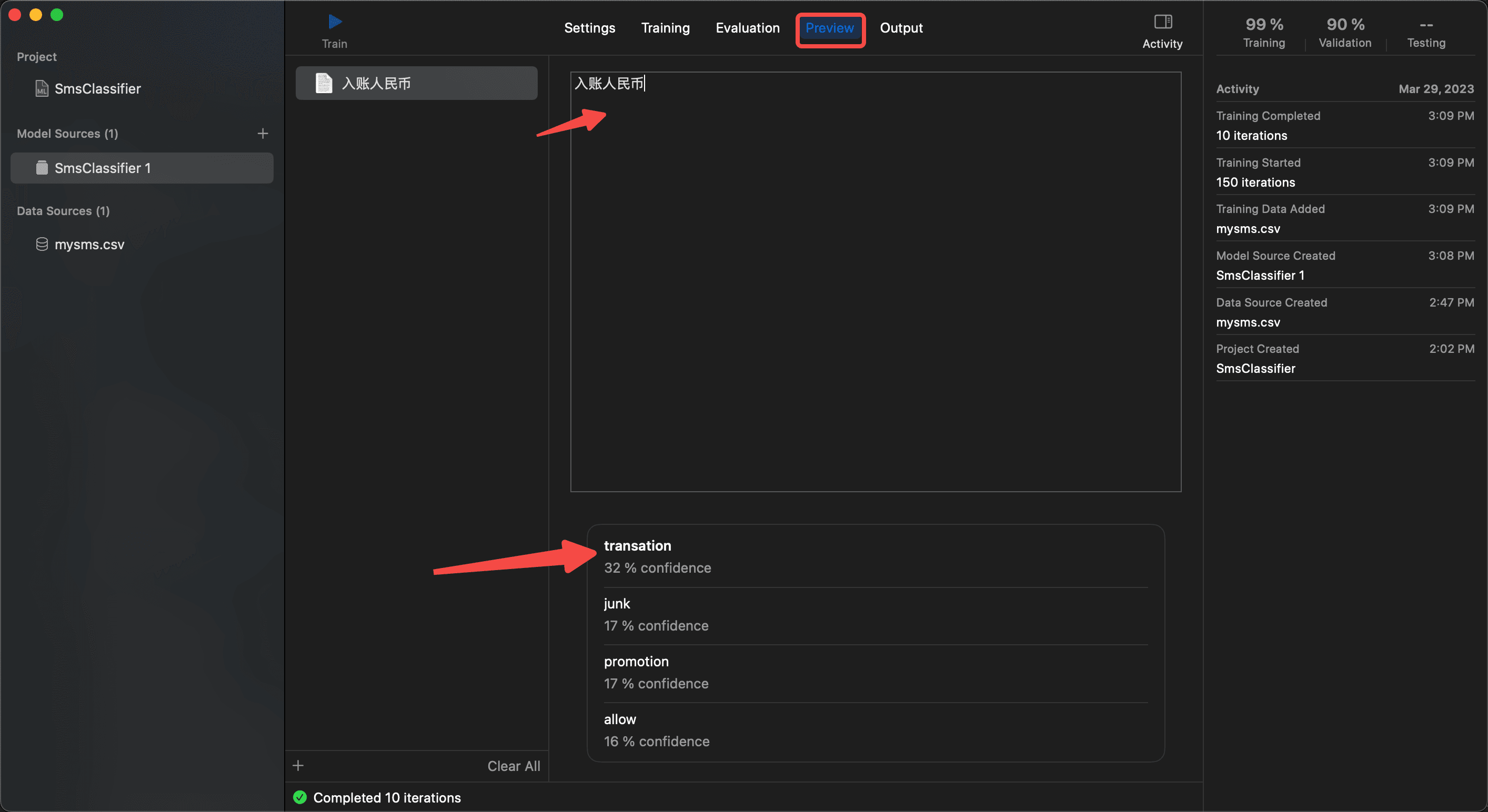
等训练好了之后,可以点击 Preview,模拟短信文本,看输出的预测,如下图:
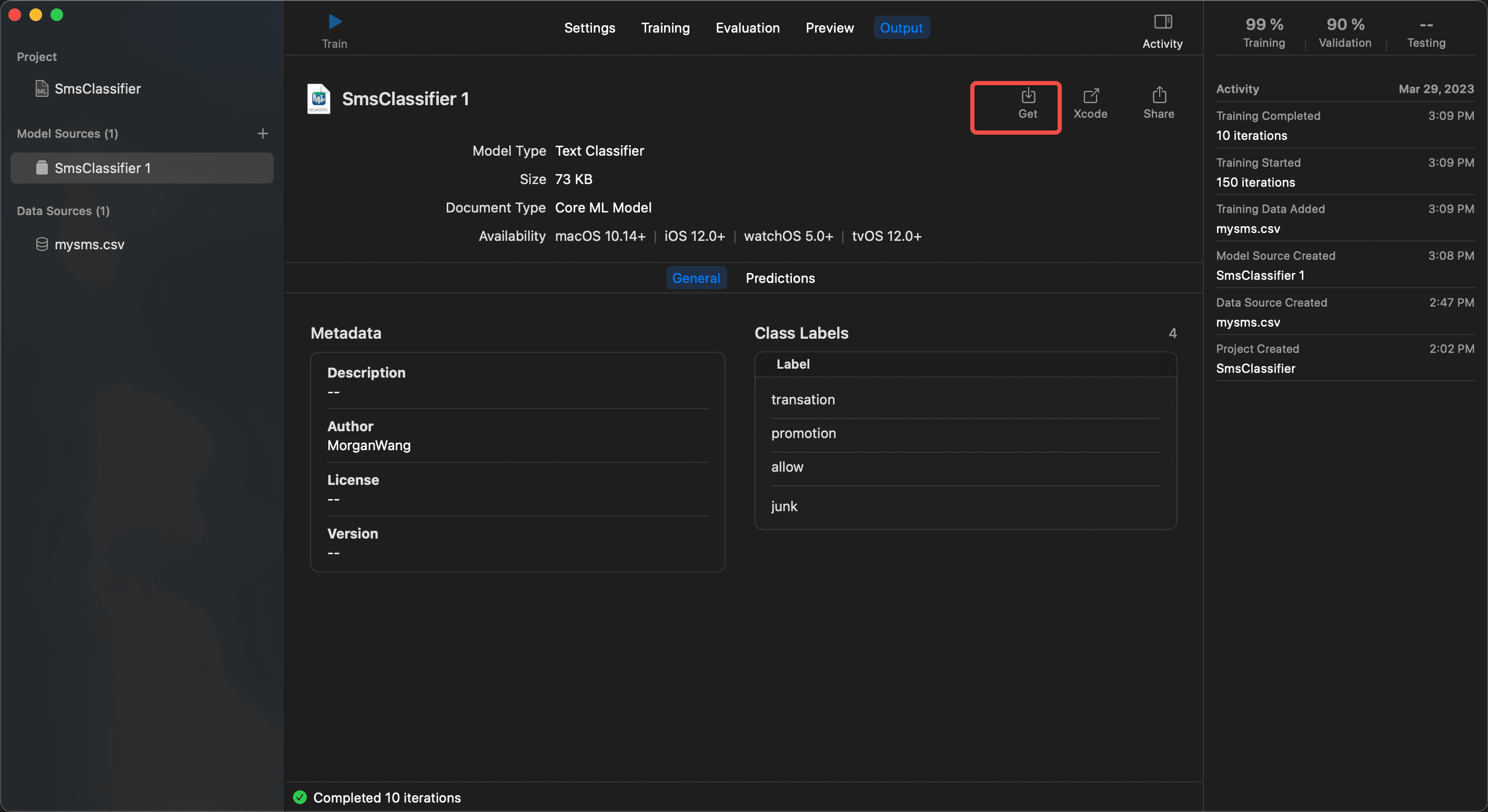
最后,导出模型,供 APP 使用
APP 开发#
新建项目,然后使用new bing 生成图片来设计 APPIcon,再用 ChatGPT-4,来生成 APP 名字。然后添加Message Filter Extension Target,如下图:
在 MessageFilterExtension.swift 中,能看到苹果已经帮忙实现了基本的框架,只需要在框架对应 // TODO: 的地方,加入对应的过滤逻辑即可。
然后导入训练结果集到项目中,注意 Target 要勾选主工程和Message Filter Extension 的 Target,因为需要在这个 Target 中使用模型来实现过滤。
具体使用如下:
import Foundation
import IdentityLookup
import CoreML
import IdentityLookup
enum SMSFilterActionType: String {
case transation
case promotion
case allow
case junk
func formatFilterAction() -> ILMessageFilterAction {
switch self {
case .transation:
return ILMessageFilterAction.transaction
case .promotion:
return ILMessageFilterAction.promotion
case .allow:
return ILMessageFilterAction.allow
case .junk:
return ILMessageFilterAction.junk
}
}
}
struct SMSFilterUtil {
static func filter(with messageBody: String) -> ILMessageFilterAction {
var filterAction: ILMessageFilterAction = .none
let configuration = MLModelConfiguration()
do {
let model = try SmsClassifier(configuration: configuration)
let resultLabel = try model.prediction(text: messageBody).label
if let resultFilterAction = SMSFilterActionType(rawValue: resultLabel)?.formatFilterAction() {
filterAction = resultFilterAction
}
} catch {
print(error)
}
return filterAction
}
}
然后在MessageFilterExtension.Swift中offlineAction(for queryRequest: ILMessageFilterQueryRequest) -> (ILMessageFilterAction, ILMessageFilterSubAction)方法调用,如下:
@available(iOSApplicationExtension 16.0, *)
private func offlineAction(for queryRequest: ILMessageFilterQueryRequest) -> (ILMessageFilterAction, ILMessageFilterSubAction) {
guard let messageBody = queryRequest.messageBody else {
return (.none, .none)
}
let action = MWSMSFilterUtil.filter(with: messageBody)
return (action, .none)
}
这里需要注意下 APP 最低版本设置,ILMessageFilterSubAction只有 iOS 16 以上的手机才支持,而ILMessageFilterSubAction则是 iOS 14 以上。
如果想实现更精细的SubAction的过滤,则上面短信数据集的 label 需要改为更精细的 label,然后训练出模型,再用来判断。
另外,ILMessageFilterQueryRequest中可以获取到sender和messageBody,所以如果想实现自定义规则,比如针对某个手机号设置对应的规则,则需要从 APP 中设置对应的规则,然后通过 Group 共享到 Extension,然后在上面的方法里通过规则匹配。
总结#
相信通过上面的步骤,大家都能开发出自己的短信过滤 APP。
上面的步骤是通过固定的训练模型来匹配的逻辑,步骤是:
- 获取短信数据集
- 通过 CoreML 使用数据集训练并生成模型
- 在项目中使用模型,进行判断
这种方式生成的模型其数据固定,每次更新模型需要重新训练并导入,然后更新 APP。是否有更好的方式呢?
比如是否可以在 APP 中边训练边更新?又或者是否可以通过本地规则加本地模型加网络模型这种方式?
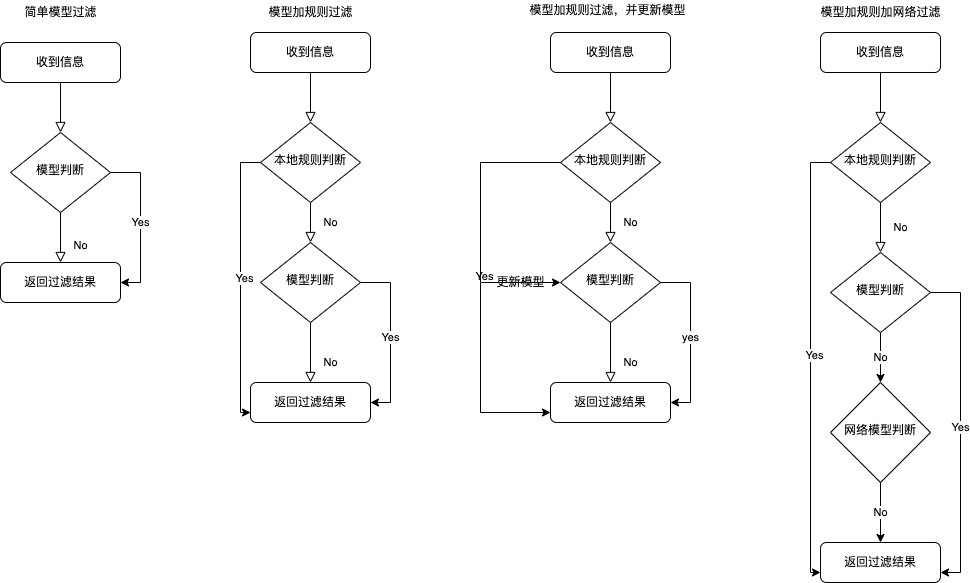
假设方案一:
首先,在 APP 中边训练边更新,大概思路如下:
更新模型,需要知道一条数据的内容和数据的分类,所以如果要在 APP 中训练模型,就需要通过另外的办法获取到分类,要不然用模型得到分类再回过头来训练模型,意义不大。所以通过自定义规则获取到数据分类,然后用数据和数据分类来更新模型,这种方式应该是可行的。
假设方案二:
然后来考虑更完善的一种方式,即通过本地规则加本地模型加网络模型的方式:
逻辑是首先通过本地规则匹配,如果本地规则匹配不到,则继续使用本地模型匹配,如果本地模型也匹配不到,则通过请求服务端,服务端另有一套不断训练更新的模型,来获取对应的分类,最后每次更新时把服务端当前对应最新的模型更新到项目中。
假设方案三:
方案二需要通过网络模型,假设的前提是服务端有一套不断训练更新的模型,那如果这个假设不存在?只有本地规则和本地模型,外加偶尔获取到的更新数据集,是否有办法在线更新本地模型?
目前本地模型是直接添加到 APP 主 Bundle 中,可以考虑在首次启动时拷贝到 APP 和 Extension 的共享 Group 中,每次打开 APP 时,判断模型是否有更新,有更新则下载替换这个目录下的模型文件。在 Extension 中,通过 URL 获取这个目录下的模型文件来进行过滤。
几种方案流程图如下:
总结如下: